De-Risk Your Data to Accelerate Your Cloud Journey: Part 3 — Turning Design into Reality
Reducing the risk of your data while moving it to the cloud can help you get early wins in your cloud journey without adding unnecessary risk to your business.
Part 1 of this series can be found here, which covers the history of how highly-regulated and/or risk-averse (from here known as HRRA) companies became gun-shy to move large sets of data to the public cloud. Part 2 of this series can be found here, which dives deeper into how you can accelerate your cloud journey with the De-Risk Data Pipeline and potential pitfalls that could arise.
But let’s be real: as of now, we haven’t talked about HOW to do anything yet. That changes now.
Designing the De-Risk Data Pipeline
Ok sounds good, but how do I actually create a de-risk data pipeline and lower my barrier to entry in the public cloud?
Disclaimer: Parts 1 and 2 of this series have been purposely tech and cloud-agnostic. This is because I believe these principles and design patterns should be applied no matter what public cloud service provider you choose. But I do work for Google, and part of the reason I came to work here was because I believe Google Cloud Platform (GCP) has the tech stack and processes to be the least risky cloud for your data. Everything after this point will be pretty GCP heavy.
Below are the reasons I believe GCP is best positioned to be the least risky cloud for your data analytics journey.
Why GCP is the Least Risky Cloud for Your Data
- Cloud Data Loss Prevention (DLP) — When you ask people to rattle off GCP’s services, it’s usually tools like BigQuery, Kubernetes Engine, Cloud Run, and Dataflow, among others. This is with good reason: they are all fantastic, differentiated products that bring tremendous value to customers. But for me the service that does not get the love it deserves is Cloud DLP: from my perspective the very best sensitive data detection and protection tool on the planet. Cloud DLP is best suited to serve as the “Classify,” “Redact,” and “Tokenize” boxes represented in Figure 2 of Part 2 of this blog. Go ahead and play with the DLP Demo right now to see how powerful the technology is. For example, if you start typing my name and type “Eric,” it says it’s “possible” it’s a name. And as soon as you start typing my last name “McCarty” it instantly recognizes it as a high likelihood of being a name, and even gets my first and last name right. It’s able to do this by using Google’s expansive training datasets and machine learning prowess to constantly improve accuracy, whereas most other sensitive data detection tools use simple pattern-recognition, which is error-prone. Cloud DLP is the key component of your de-risk data pipeline. We’ll have more on this later.

- Privacy and Security Built In — Ok, this is kind of a catch all, but Google does take great pride in its privacy and security posture. Examples include the Google-designed Titan chip to establish hardware root of trust for GCP servers, Google’s zero trust model of security, and Google’s Project Zero finding and patching some of the world’s biggest vulnerabilities like Spectre and Meltdown before they could be exploited on GCP. But one I focus on is Google’s network, which carries more than 25% of the world’s internet traffic. This gives GCP an advantage in routing traffic across a private backbone rather than the public internet. Whereas most cloud providers try to offload traffic to the public internet to reduce costs, Google tries to keep traffic on the private network as long as possible to improve privacy (along with reliability and performance).

- Google Cloud Risk Protection Program (Shared Fate) — As described earlier, generally cloud providers invoke a shared responsibility model: the public cloud provider is responsible for physical and infrastructure security, and the customer is responsible for application and data security. This causes long cycle times on legal agreements with cloud customers and the aforementioned “security and governance being close to perfect” scenarios before moving data to the cloud. Google is the first to introduce the Risk Protection Program, which moves customers to a shared fate instead of a shared responsibility model. This isn’t to say there still isn’t responsibility with the customer, but it is a unique offering in the public cloud to help ease the burden of risk companies may feel.

Design Options for the De-Risk Data Pipeline
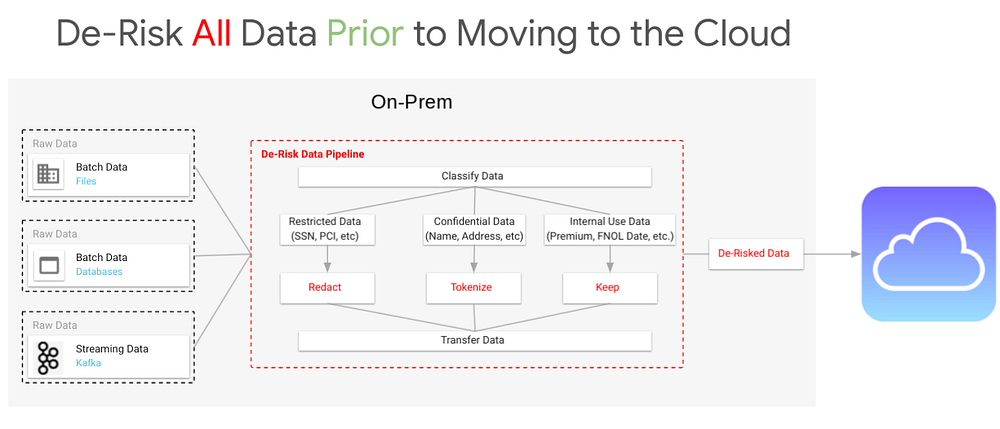
Let’s take another look at the high-level design of the De-Risk Data Pipeline from Part 2 of this series:

There are a number of considerations that need to be made based on this design.
- Where to run the pipeline. You can run this pipeline fully on-prem, fully in the cloud, or hybrid. The advantage of fully on-prem is that you can ensure that no sensitive data is exposed in the public cloud. The disadvantage is that you are stuck with managing and scaling infrastructure on-prem, coordination of pipelines across data centers, and you lose some of Cloud DLP’s most feature-rich functionality. You can also run a hybrid model that detects/redacts the most sensitive of data assets (The “Restricted Data” funnel) on-prem, and does the most complex (but less risky) functions in the cloud. Recommendation: Push all raw data to highly locked-down zone of the cloud, run your pipeline, and publish your de-risked data to its destination. This allows you to take advantage of the cloud, and data exposure would be minimal.
- How to trigger the pipeline. It may seem trivial, imagining moving one piece of data through a pipeline is easy. But when the pipeline scales to hundreds or thousands of assets, it can get complicated very fast. How to actually kick off the pipeline becomes a key decision: you can create separate instances of the pipeline for each asset or have a mass pipeline that runs in regular intervals that collects and processes all assets that are “ready.” The advantage of separate instances is scope: it can run as soon as the individual asset is ready, and any failure only effects one particular instance. It also feels more comfortable to those used to doing data engineering with traditional tooling (legacy ETL tools worked in a “one asset at a time” paradigm too). The challenge with this approach is scale and time to market. Managing hundreds or thousands of jobs gets very complicated, especially when assets arrive at different intervals or there is frequent changes to the pipeline that has to apply to everything. Recommendation: Run your pipeline in moderate size batches at a regular interval (every 15 mins is popular). “Process what’s ready” for a particular domain or business area at a size that can be effectively managed. Another plug for GCP here, Cloud Dataflow is the perfect tool for this as it will scale based on the amount of work it needs to do. If you have very light workloads at night, and a heavy workload at the end of the month, Dataflow can scale with those needs without teams having to manage and provision infrastructure appropriately up front.
- Historical vs. Incremental Loads. One thing that I often see missing from data pipeline articles and blogs is the lack of distinction of historical and incremental pipelines. Very rarely do you start a data pipeline with only fresh data, but instead need to load 3, 5, 25 years or more of historical data first for the dataset to be complete. And it’s very likely you will need a different set of tooling for your historical loads than your incremental (especially if incrementally will be streaming vs. historical batch). This can be a challenge if you are trying to classify and protect data as it’s moving, and it’s painful to create a bunch of code for what is essentially a one-time move. Recommendation: Similar to the first consideration, this gets significantly easier if you push raw data to the cloud, and process your pipeline there. You may need to use something like Storage Transfer Service for large historical loads, Cloud Storage PUT Object for incremental batch loads, Cloud Pub/Sub for streaming ingestion, Datastream for CDC ingestion, among other ingestion methods. But if you have to fit in a classification and protection strategy in each of those methods, it gets difficult to maintain and may result in different output. Ingest raw data into a locked down cloud storage bucket, and then you can leverage Dataflow to scale to either historical or incremental size processing without up-front provisioning of infrastructure. And as an added bonus, you can have a unified codebase for classification and protection for historical, incremental batch, and incremental streaming data.
Putting it All Together
With these considerations in mind, what does a de-risk data pipeline look like? Below is an example high-level reference architecture:

The major components consist of:
- Multiple Ingestion Pipelines: Many companies will try to sell you a one-size-fits-all solution. But generally speaking, unless you are incredibly lucky to work in an environment with a homogeneous data source, you’ll need the right tool for the job. The important part is having a consistent destination, with cloud storage being the most readily accessible to all types of data sources.
- Classify and Protect: The meat and potatoes of the pipeline, Dataflow is best suited for this due to it’s ability to scale to the workload. I suggest running this in batch at a regular interval for all assets in a particular, manageable domain, as described above. As described in Part 2 of this blog series, your complexity will increase as you add the number of elements you want to protect, but errors or issues will occur at times regardless. Build an error queue for data that fails your confidence threshold for protection that can be triaged, approved/rejected, and re-processed on a future run rather than a hard stop. Leveraging DLP as the brains of your classify and protect functions will greatly reduce your data risk as your pipeline moves data outside of the highly-secure zone.
- Democratized Analytics: At the end of the process is the crown jewel: a de-risked analytics environment that empowers your company to make business decisions without the data risk usually associated with analytics in the cloud. BigQuery, the strongest Leader in the Forrester Wave for Cloud Data Warehouses, is an obvious choice to accelerate your analytics journey from here.
These are just guidelines, there are many factors to consider when doing something similar for your organization. I would love to hear modifications or other ideas you have to reduce data risk as you move your analytics workloads in the cloud. Drop me a line if you’d like to discuss or pontificate: emccarty@google.com or connect with me on LinkedIn.
*Bonus: if you’d like to explore a tutorial on building a pipeline using DLP and Cloud Functions, a process that works great for incremental batch flows, feel free to follow the steps listed here. It will give a good perspective on what it would take to fit the needs of your company.

{kind=link}